25 janvier 2024
L’envers du décor de ChatGPT
Comment une machine peut-elle écrire un texte complexe aussi bien qu'un être humain? Le professeur de mathématiques Nicolas Doyon apporte quelques réponses.

'%3e%3cpath%20d='M306.615%2079.694H144.011L892.476%201150.3h162.604ZM0%200h357.328l309.814%20450.883L1055.03%200h105.86L714.15%20519.295%201200%201226.37H842.672L515.493%20750.215%20105.866%201226.37H0l468.485-544.568Z'/%3e%3c/g%3e%3c/svg%3e)



Lancé à la fin novembre 2022, ChatGPT a rapidement ébahi la planète par ses performances ahurissantes. L'application de génération de texte a effectivement su leurrer nombre de lecteurs, même parmi les plus attentifs, qui n'ont pu distinguer les textes produits par l'intelligence artificielle (IA) de ceux écrits par un être humain. Mais comment ce que plusieurs croyaient hier encore impossible est-il devenu si vite réalité?
«L'explication à cette montée rapide de l'intelligence artificielle et de ChatGPT peut être vue comme un triangle dont les trois sommets sont aussi importants. Premièrement, la puissance de calcul des ordinateurs a beaucoup augmenté. Deuxièmement, la quantité de données de qualité pour entraîner les réseaux de neurones a explosé. Troisièmement, il y a eu plusieurs innovations dans l'architecture des réseaux de neurones», expose le professeur Nicolas Doyon.

Nicolas Doyon, professeur au Département de mathématiques et de statistique et chercheur au Centre de recherche CERVO, a expliqué la montée de l'IA et de Chat GPT dans sa conférence «Les secrets mathématiques de ChatGPT».
Invité par la Formation continue de la Faculté des sciences et de génie à prononcer une conférence grand public sur le sujet, ce professeur du Département de mathématiques et de statistique et chercheur au Centre de recherche CERVO, a évoqué quelques jalons de l'histoire de l'IA et vulgarisé certains principes scientifiques et mathématiques sur lesquels repose le succès de la célèbre application informatique.
Une machine championne d'échecs
L'un des plus grands coups d'éclat de l'intelligence artificielle remonte à 1996 lorsque l'ordinateur Deep Blue a réussi à battre le champion du monde des échecs Garry Kasparov. Deep Blue était programmé pour créer un arbre de possibilités, attribuer une valeur aux positions finales des différentes branches de l'arbre, puis déterminer le meilleur coup possible.
Cette approche qui fonctionnait bien aux échecs était toutefois moins adaptée au jeu de go, dont le plateau forme un quadrillé de 19 x 19 – ce qui donne beaucoup plus de possibilités de coups que le format 8 x 8 des échecs. Même pour un ordinateur, l'arbre de possibilités devenait trop grand. «C'est pourquoi, raconte Nicolas Doyon, des chercheurs se sont alors dit: “Ça ne ressemble pas du tout à notre façon de penser. Comment pourrait-on s'inspirer du fonctionnement du cerveau et des neurones humains pour améliorer l'intelligence artificielle?”»
Imiter les neurones
En étudiant le fonctionnement des neurones humains, on a découvert qu'ils ne réagissent pas à tous les messages qu'ils reçoivent. Un message doit atteindre un seuil minimal pour que le neurone émette ce qu'on appelle un potentiel d'action, qui, lui, a toujours la même force et la même forme, quelle que soit l'intensité du message initial. Ce potentiel d'action est transmis au neurone suivant grâce à une synapse. C'est la loi du tout ou rien.
Toutefois, les synapses ne servent pas uniquement à transmettre l'information d'un neurone à l'autre; leur plasticité jouerait un rôle central dans l'apprentissage. Les chercheurs ont, en effet, remarqué que la force de connexion des synapses évolue avec le temps. «De manière simplifiée, plus une synapse est utilisée, c'est-à-dire plus elle propage un potentiel d'action vers le neurone suivant, plus elle devient forte. On voit bien au microscope que, lorsqu'une personne apprend, l'épine dendritique, une région du neurone, devient plus grosse. Bref, en devenant plus grosse et plus forte, la synapse modifie peu à peu notre manière de penser», spécifie le professeur.
Comment représenter mathématiquement ces faits biologiques? «Une des manières de traduire en mathématique la loi du tout ou rien, répond Nicolas Doyon, est d'utiliser la fonction de Heaviside.» Souvent, en mathématiques, les fonctions passent de 0 à 1 de manière continue. «La fonction de Heaviside, quant à elle, précise-t-il, est une fonction qui vaut 0 jusqu'à ce que l'entrée de la fonction atteigne un certain seuil. Alors, elle passe soudainement à 1.»
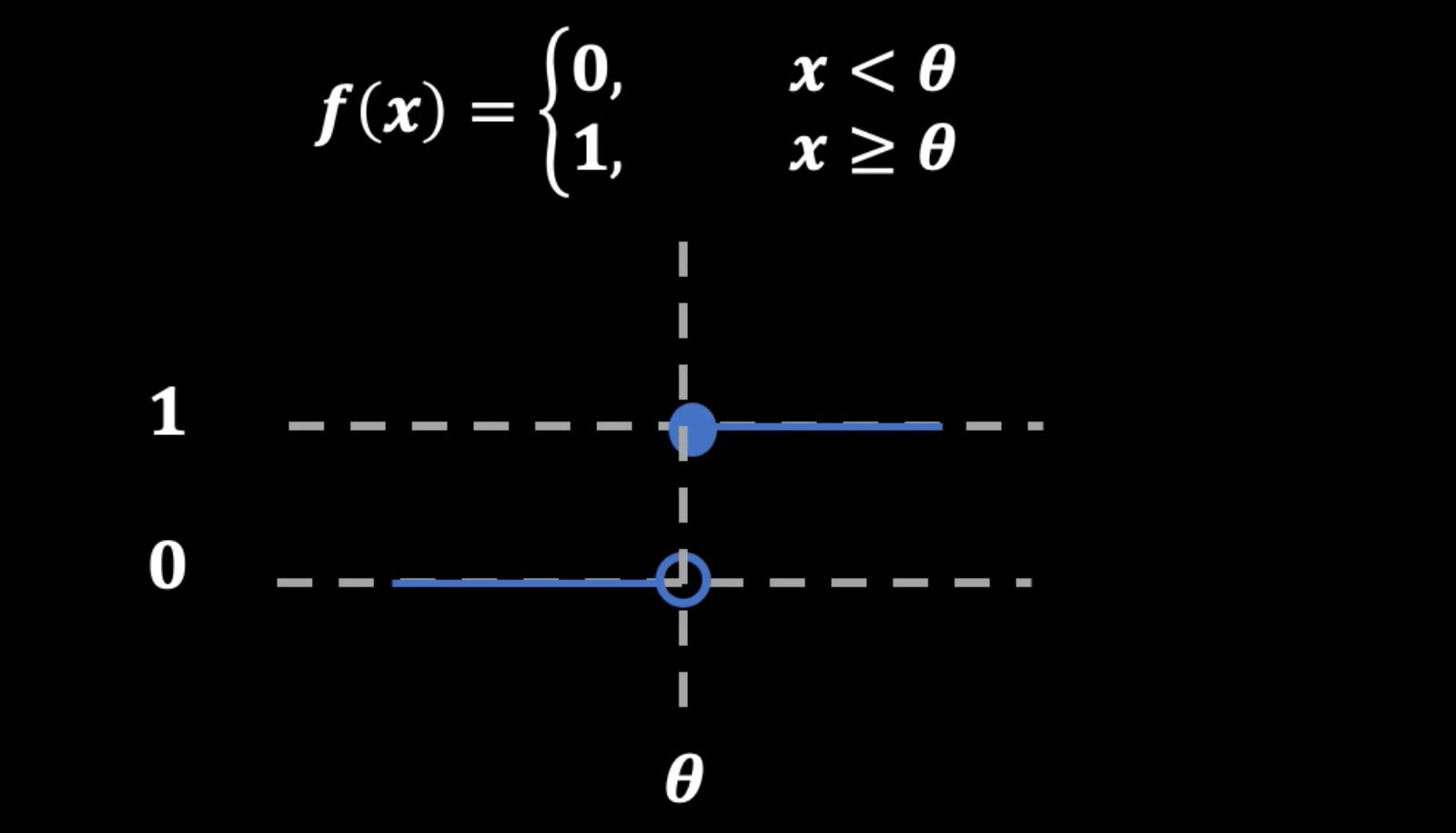
Le tout ou rien peut être représenté mathématiquement par la fonction de Heaviside.
«Pour représenter le rôle des synapses, ajoute-t-il, on attribue des poids aux différentes entrées du neurone.» Sur le graphique, on peut voir que, après avoir établi les valeurs numériques des entrées, on multiplie ces valeurs par le poids de la synapse, on additionne les résultats de ces multiplications pour obtenir une somme pondérée et, finalement, on regarde si cette valeur de sortie atteint le seuil requis, ce qui se traduira par 0 ou 1.
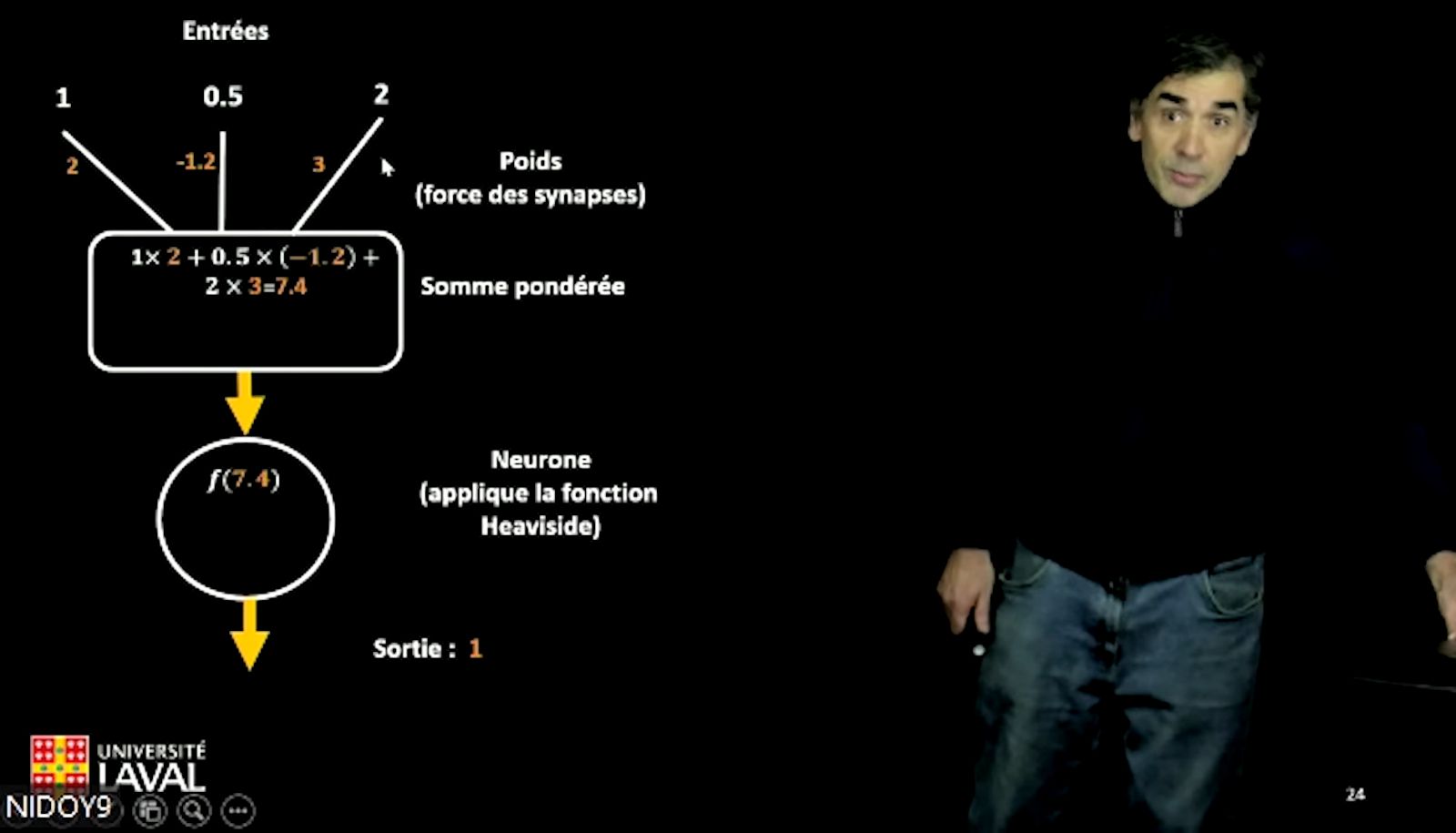
«Pour représenter le rôle des synapses, on attribue des poids aux différentes entrées du neurone», explique le professeur Nicolas Doyon.
Entraîner le réseau
Au cours des dernières années, l'intelligence artificielle a réussi à faire de grandes percées grâce au développement de l'apprentissage profond. «On travaille désormais avec des réseaux de neurones à plusieurs couches: une couche d'entrée, des couches intermédiaires et une couche de sortie. Entre un neurone d'une couche et un neurone d'une autre couche, il y a une force de connexion, aussi appelée poids synaptique, et lorsque le réseau apprend, chacun de ces poids est ajusté», remarque Nicolas Doyon.
Et comment le réseau apprend-il? Par entraînement, indique le chercheur. Prenons le cas d'un réseau de neurones à qui on demande de confirmer si la photo est celle d'un chat ou d'un chien. On attribuera la valeur 0 au chat et 1 au chien. Pour entraîner le réseau, on utilisera des milliers, voire des millions d'images de ces petites bêtes, et on examinera le pourcentage des images bien classées. Si le réseau ne donne pas la bonne réponse, c'est qu'il n'a pas obtenu la bonne valeur de sortie parce que les poids synaptiques n'étaient pas bien ajustés. On réajustera donc ces poids jusqu'à obtenir un pourcentage de réussite très élevé.
Mais comment faire pour ajuster les poids? «On utilise, entre autres, la méthode de descente de gradient. Pour l'illustrer, on peut imaginer une personne qui essayerait de descendre le plus rapidement possible jusqu'au pied d'une montagne. C'est facile à visualiser lorsqu'il y a seulement deux entrées. Sur l'axe des x, on va présenter le taux de réussite lié à différents poids par lesquels on a multiplié la première entrée et, sur l'axe des y, le taux de réussite lié à différents poids par lesquels on a multiplié la seconde entrée. Sur l'axe des z apparaîtra l'erreur. Il est alors possible de visualiser le point où l'erreur est la plus faible et de tenter d'ajuster les poids pour tendre vers cette direction», explique le professeur Doyon, qui ajoute du même souffle que le principe, bien que toujours le même, est plus ardu à visualiser dans la réalité lorsque le nombre de paramètres à ajuster se compte par millions, voire par milliards.
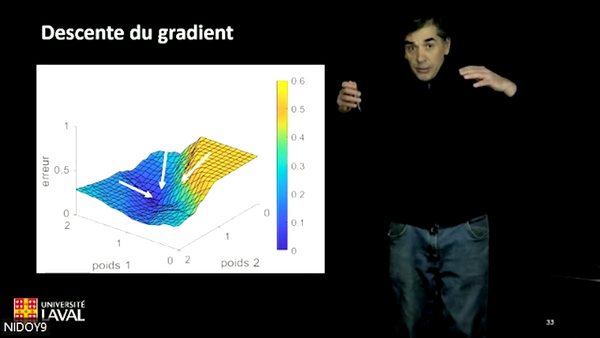
On ajuste les poids synaptiques avec la méthode de descente de gradient.
Mathématiques et lecture au cœur de ChatGPT
Les chiffres exacts ne sont bien sûr pas publiquement révélés, mais on peut estimer que ChatGPT possède un réseau de 60 à 80 milliards de neurones, de 96 couches et de 175 milliards de poids à ajuster. À titre comparatif, il y a environ 85 milliards de neurones dans le cerveau humain. «La comparaison demeure un peu boîteuse, convient Nicolas Doyon, parce que nos neurones ne sont pas exactement comme des neurones artificiels, mais on est à peu près dans le même ordre de grandeur.»
Lorsqu'on demande à l'application informatique de se définir elle-même, elle répond: «ChatGPT utilise une structure de réseau neuronal profond. Il est important de noter que ChatGPT ne possède pas de compréhension profonde ou de conscience de soi. Les réponses sont basées uniquement sur les probabilités statistiques des mots ou des phrases.» Ainsi, pour générer un texte, ChatGPT va calculer, à partir d'une séquence de mots, les probabilités qu'une autre séquence de mots la suive, puis proposer la suite la plus probable.
Pour y arriver, ChatGPT a dû s'entraîner sur des milliards de données. La teneur de cette lecture tient bien sûr du secret professionnel. Cependant, on peut supposer que le réseau a été entraîné à partir de plus de 300 milliards de mots. «Si vous lisez 300 mots par page et une page par minute, pendant 24 heures par jour, vous devrez lire pendant 1900 ans pour ingérer autant d'informations», illustre le mathématicien pour aider à se faire une idée de l'ampleur de la bibliothèque à la base de l'apprentissage de ChatGPT.
— Nicolas Doyon, à propos des 300 milliards de mots qui, suppose-t-on, ont composé la banque de données d'entraînement de ChatGPT
Entre émerveillement et craintes
Les performances parfois époustouflantes de ChatGPT nourrissent l'imagination de certains, qui voient le futur comme un film de science-fiction où les intelligences artificielles dominent le monde. Ce n'est toutefois pas ce scénario qui inquiète ceux qui, parmi les scientifiques, aimeraient qu'on encadre mieux le développement de l'IA. Leur intention est plutôt de prévenir certains dérapages liés à l'utilisation que pourraient en faire les êtres humains. Ils veulent aussi qu'on prenne le temps de mieux comprendre et analyser les répercussions négatives de cette technologie.
«Qu'est-ce qui pourrait mal se passer? Évidemment, des étudiants peuvent utiliser ChatGPT pour tricher. Également, des gens peuvent perdre leur travail. Récemment, les auteurs en grève à Hollywood ont demandé de limiter l'usage de l'IA dans la scénarisation», rappelle Nicolas Doyon.
De plus, révèle le professeur, d'autres problèmes sont moins apparents et plus sournois. «Par exemple, dit-il, dans le domaine de la reconnaissance faciale, l'IA reconnaîtrait plus facilement les hommes blancs que les femmes ou les personnes issues de minorités visibles. Ce fait surprend un peu parce qu'on imagine une intelligence artificielle neutre. Ça ne peut pas être sexiste ou raciste. Mais comme l'IA a probablement été entraînée à partir d'une base de données qui contenait plus de visages masculins et blancs, elle a hérité de nos défauts.»
Un autre exemple que donne le professeur vient de DeepL, une application de traduction qui utilise les mêmes principes que ChatGPT. «Si on demande à DeepL de traduire “elle lit” en hongrois, dit-il, il nous donnera “ὄ olvassa”. Si on lui demande de traduire les mêmes mots hongrois en français, il donnera “il lit”». Pourquoi? Parce que la base de données comporte un biais statistique, le sujet masculin se trouvant plus fréquemment devant le verbe «lire».
Souvent occulté, le problème environnemental n'est pas non à prendre à la légère. «Les gens pensent que l'IA, c'est virtuel et que ça n'a pas de répercussions sur l'environnement. Pourtant, selon un article, chaque fois que vous lui parlez, ChatGPT boit 500 ml d'eau. Cette image a été employée pour rappeler que, pour refroidir les supercalculateurs, ça prend une énorme quantité d'eau. En plus de cette ressource, ChatGPT demande aussi beaucoup d'énergie. Certains disent que l'IA va bientôt consommer autant d'électricité qu'un pays au complet», soutient le professeur Doyon.
Alors, quel est l'avenir de l'IA et de ChatGPT? «Je ne sais pas», répond en toute modestie le professeur Doyon. «Y a-t-il des choses que ChatGPT ne réussira jamais à faire. Je n'ai pas de réponse. Chaque mois, on entend dire que Chat GPT a fait une nouvelle chose. Il est impossible de savoir où tout cela va s'arrêter», conclut le mathématicien.
Pour un aperçu des travaux de Nicolas Doyon
En savoir plus sur les rendez-vous passés et à venir des conférences grand public organisées par la Formation continue de la Faculté des sciences et de génie
Visionner la conférence «Les secrets mathématiques de ChatGPT»: